 Exploring the WordStar file format
Exploring the WordStar file format
As an early entry in word processing, WordStar’s file format is quite simple.
One of the most significant developments in technical and professional writing is the word processor, which allows the writer to see what the page might look like as they are writing it. The word processor made it possible for non-experts to create professional documents quite easily and inexpensively.
The US Library of Congress notes in its entry about the WordStar file format family that “WordStar was one of the most influential word processing formats in early computing.” Citing Kirschenbaum, the Library of Congress continues:
… as one of the first word processors, WordStar helped change the game for writers because it allowed them fast, direct, and intimate control over the text and how it would look on a printed page. WordStar processor was the first to render the document on screen as it would appear when printed, including page, margins, and justification.
As an early entry in word processing, WordStar’s file format is quite simple. Essentially, it’s a mixture of nroff-like dot commands for page formatting combined with control characters for specific character formatting.
Dot commands
WordStar supported several dot commands to control page layout and paragraph formatting. The Library of Congress links to a scanned PDF WordStar 3.0 reference card which is reproduced below as images:

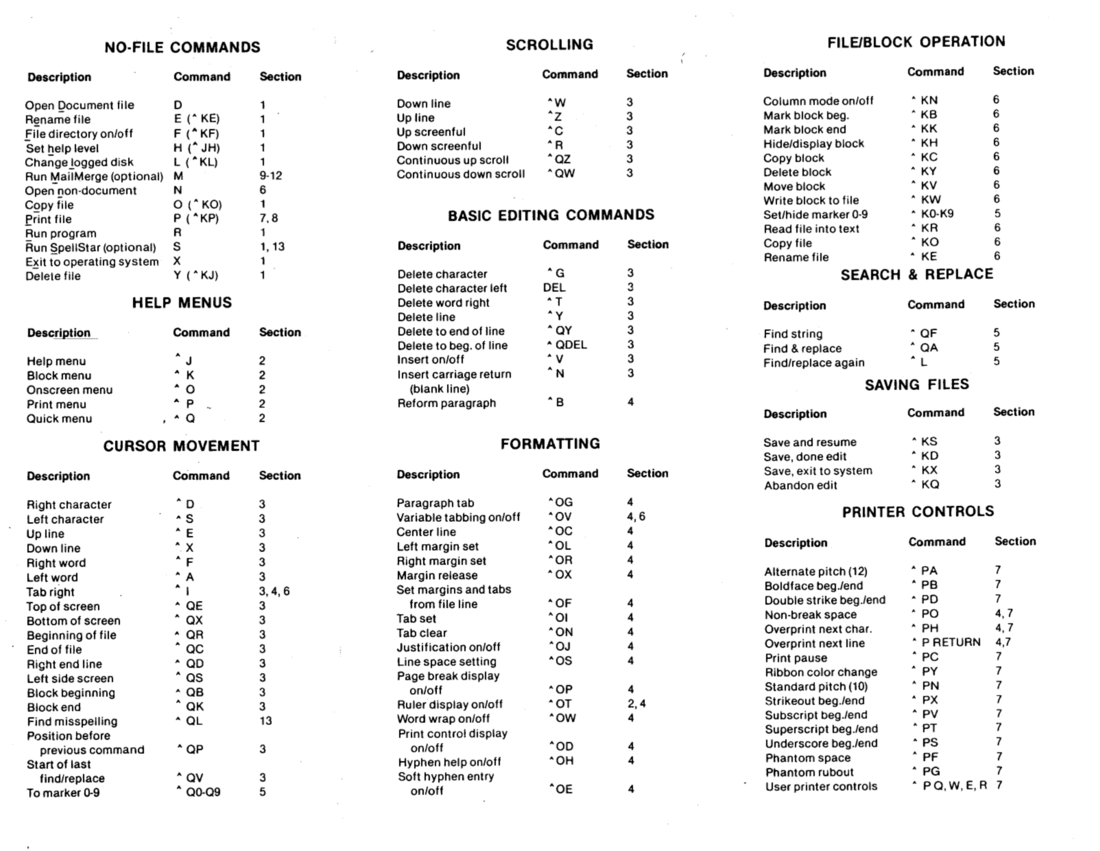
WordStar 3.0 allowed the user to control page layout and the printer
using these dot commands: (these are initially sorted, but arranged for
consistent ordering - for example, .FM follows
.FO even though they would sort as .FO then
.FM)
| Dot command | Description |
|---|---|
.BP |
Bidirectional printing on/off |
.CP |
Conditional page |
.CW |
Character width |
.FO |
Footing |
.FM |
Footing margin |
.HE |
Heading |
.HM |
Heading margin |
.IG |
Ignore (comment) or .. |
.LH |
Line height |
.MB |
Margin at bottom |
.MT |
Margin at top |
.OP |
Omit page number |
.PA |
Start a new page |
.PL |
Page length |
.PN |
Page number |
.PC |
Page number column |
.PO |
Page offset |
.SR |
Subscript and superscript roll |
.UJ |
Micro justify on/off |
For example, to set the output to use ten characters per inch (called pica pitch) the user would include this statement:
.CW 12To print output using twelve characters per inch (elite pitch) the user would enter this command:
.CW 10Values for any dot command may only be whole numbers. The range for
the .CW character width command is between 24 wide (which
results in five characters per inch) and 4 wide (thirty characters per
inch). The default is 12 wide, or ten characters per inch.
Similarly, to set the line height to exactly 6.0 lines per inch (which is typical for typewriter-like output) the user would type this dot command:
.LH 8The .LH line height command can range between 24 tall
(which gives 2.0 lines per inch) and 5 tall (or 9.6 lines per inch).
WordStar also supported a “Mail Merge” feature, using these dot commands: (initially sorted, then arranged)
| Dot command | Description |
|---|---|
.AV |
Ask for variable value |
.CS |
Clear screen |
.DF |
Data file |
.DM |
Display message |
.FI |
File insert |
.LM |
Left margin |
.RM |
Right margin |
.LS |
Line spacing |
.OJ |
Output justification |
.IJ |
Interpret input as already justified |
.PF |
Print-time line formation |
.RP |
Repeat |
.RV |
Read variable |
.SV |
Set variable |
Character codes
The Library of Congress documents the WordStar file format family as using single-byte characters but “7-bit ASCII code for printable characters as outlined in the File Format for WordStar Release 7.0, an ad hoc specification released in 1992 by WordStar International Incorporated.” The copy cited by the Library of Congress, as currently archived at sfwriter.com, indicates that “All codes below 20h are reserved for control information, and the high (8th) bit on characters is likewise used to convey information about formatting and document control.”
Modern computers store data in 8 bit groups, called a byte. Each bit is a 1 or 0 binary value, and each position in the byte represents a power of 2, counting from right to left. This is not as foreign as it might initially seem; the numbers we use every day are made up of single digits from 0 to 9, where each position represents a power of 10, from right to left. For example, the value 789 is a three-digit value with a 9 in the “ones” place (10^0), an 8 in the “tens” place (10^1) and a 7 in the “hundreds” place (10^2).
Binary numbers work the same, but with 1 and 0. The rightmost position represents “1” (2^0). Moving from right to left, the positions represent “2” (2^1) to “128” (2^8). The binary value 00000001 is “1,” the value 10000000 is “128.” For example, the value 11111111 is “256” because it’s (from right to left) “1” plus “2” plus “4” … and so on until “128.” Add them together for (from right to left) 1+2+4+8+16+32+64+128 or “256,” the maximum value that an 8-bit value can store.
WordStar used ASCII, the American Standard Code for Information Interchange, an international standard for the ordering of characters in a code table. The first 32 codes (from 0 to 31) are reserved as control characters, such as “9” to represent a tab, “10” for a new line, and so on. Values from 32 to 127 are normal characters, starting with “32” (or hexadecimal value 0x20) for a space character, and “65” (or 0x41) for the capital letter A. These values from 0 to 127 require only 7 bits; the binary value 01111111 is the number 127.
Most characters in a WordStar file are 7-bit ASCII. Normal printable characters are output as entered, such as letters, digits, and other characters shown on your keyboard. Control characters held special meaning, including these: (this is a subset)
| Value | Hexadecimal | Definition |
|---|---|---|
| 2 | 0x02 | Bold type on/off |
| 4 | 0x04 | Double strike printing on/off |
| 8 | 0x08 | Backspace, to overprint the previous character |
| 9 | 0x09 | Tab |
| 10 | 0x0a | Line feed |
| 12 | 0x0c | Page feed |
| 13 | 0x0d | Carriage return |
| 19 | 0x13 | Underline on/off |
| 20 | 0x14 | Superscript on/off |
| 22 | 0x16 | Subscript on/off |
| 24 | 0x18 | Strikeout on/off |
| 25 | 0x19 | Italic type on/off |
| 26 | 0x1a | End of file |
From the File Format for WordStar Release 7.0, all lines ended with the pair 0x0d (carriage return) and 0x0a (line feed). This is the standard character pair for terminals, later adopted by the DOS operating system.
All WordStar files terminate normal lines (paragraphs) with the sequence <0Dh, 0Ah> (carriage return, line feed). A “soft return” <8Dh, 0Ah> is inserted in the text stream at the points where lines are subject to word-wrap. A “soft space”
is inserted for tabbing, justification, and for left-margin indentation. In normal mid-paragraph lines, the blank characters (usually space) following words at the end of lines will be retained, so that the user’s text is fully retained. …
In versions of WordStar prior to 5.0, the high bit was set on the last character of all non-blank text strings that fell within the margins. The printer drivers relied on this information to determine which text was to be microjustified. This functionality was dropped in the later versions in favor of the use of absolute tabs, margin dot commands, and paragraph styles.
For example, in WordStar 4.0 (popular with many users) the word “the”
in the middle of a sentence would be encoded as t (116, or
0x74) then h (104, or 0x68). But the e (101,
or 0x65) would have the high bit set (or 10000000) so 101+128=229, to
indicate the last letter of a word that can be microjustified.
High bit meaning
We can examine this formatting for ourselves by writing a program. The basic process of the program is:
- Open a file
- Read blocks of data at a time (using
fread) - Print each character in that block of data
If the character’s value is between 0 and 31, we can print the value in brackets as a reminder that it’s a control character. For values from 32 to 127 (the normal printable character set) we can just print the character. Values at 128 or above are actually printable characters, but with the high bit set. We can use binary operations to strip this value and print it in a different set of brackets to indicate how it was stored in the file.
A sample C function to print characters in this way might look like this:
typedef unsigned char BYTE;
void show_string(const BYTE *str, size_t len)
{
size_t i;
for (i = 0; i < len; i++) {
if (str[i] >= 32) {
if (str[i] & 0x80) { /* binary 1000 000 */
printf("{%c}", str[i] & 0x7f); /* binary 0111 1111 */
}
else {
putchar(str[i]);
}
}
else {
printf("<%d>", str[i]);
}
}
}Note that the function uses a “nested” if statement to
detect when a value has a value of 32 (space) or greater. If the value
has the high bit set (using a binary and operation with the
value 10000000 to test just the high bit) the function prints the normal
character in “curly” brackets. Otherwise, normal characters are printed
as given. Characters with a value less than 32 are printed as numbers in
angle brackets.
The full program reads each file from the command line, and uses a
function to read the file in parts. For each part, the function uses the
show_string function to print the text.
#include <stdio.h>
typedef unsigned char BYTE;
void show_string(const BYTE *str, size_t len)
{
size_t i;
for (i = 0; i < len; i++) {
if (str[i] >= 32) {
if (str[i] & 0x80) { /* binary 1000 000 */
printf("{%c}", str[i] & 0x7f); /* binary 0111 1111 */
}
else {
putchar(str[i]);
}
}
else {
printf("<%d>", str[i]);
}
}
}
void show_file(FILE *in)
{
BYTE str[100];
size_t len;
while (!feof(in)) {
len = fread(str, sizeof(BYTE), 100, in);
if (len > 0) {
show_string(str, len);
}
}
}
int main(int argc, char **argv)
{
int i;
FILE *pfile;
for (i = 1; i < argc; i++) {
pfile = fopen(argv[i], "rb");
if (pfile != NULL) {
show_file(pfile);
fclose(pfile);
}
else {
fputs("cannot open file: ", stderr);
fputs(argv[i], stderr);
fputc('\n', stderr);
}
}
if (argc == 1) {
/* no files? read from standard input */
show_file(stdin);
}
}Save this as asciify.c and compile it using this
command:
gcc -o asciify asciify.cExamining files
Let’s use this program to examine the contents of four sample files, created using WordStar 4.0 on DOS.
Sample file
The first file doesn’t contain any special formatting, just two lines of text:
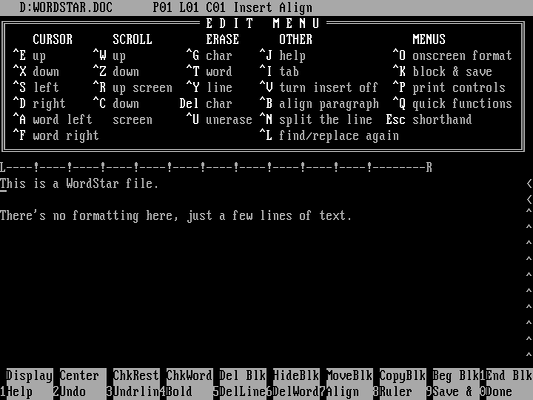
The program output shows the details of this file:
$ ./asciify WORDSTAR.DOC
Thi{s} i{s} {a} WordSta{r} file.<13><10>
<13><10>
There'{s} n{o} formattin{g} here{,} jus{t} {a} fe{w} line{s} o{f} text.<26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26>The program actually prints the output on one line, but I have added
a new line after the <13><10> pairs. These
indicate a carriage return (ASCII 13) and a line feed (ASCII 10), so the
file is easier for humans to read if we break the lines after these code
pairs.
Note that the last letter of each word has the high bit set, to indicate that WordStar 4.0 can perform microjustification here. Also, the file ends with a series of “end of file” markers (ASCII 26); WordStar 4.0 appears to save files in increments of 128 bytes, and these extra characters fill out those extra bytes. This padding appears in all the sample files.
Bold text
The next file contains one word in bold type:
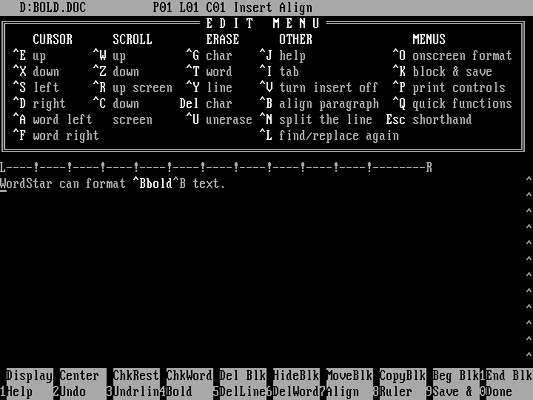
The program output shows how WordStar 4.0 uses a control character to start and end bold type formatting:
$ ./asciify BOLD.DOC
WordSta{r} ca{n} forma{t} <2>bold{} text.<26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26>The ASCII code “2” starts bold text. (The program has a bug where
it does not show the <2> to turn off bold, because
the high bit is set.)
Underlined text
The next file shows an example of underlined text:
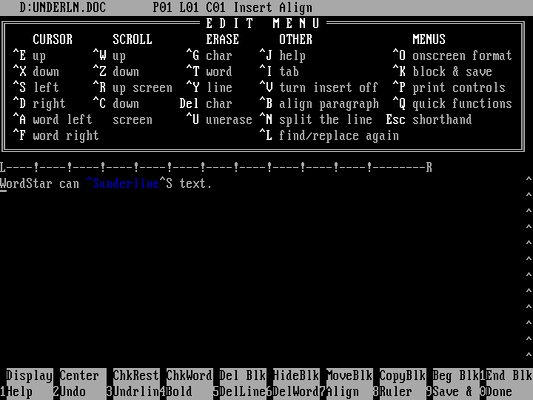
The program shows how WordStar 4.0 sets a similar control character to start and end text as underline:
$ ./asciify UNDERLN.DOC
WordSta{r} ca{n} <19>underline{} tex{t}.<26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26><26>Note that underlined text starts with ASCII code 19, and the text is again reset to normal with another ASCII 19 value with the high bit set, just as in the bold type example.
Bold and underlined text
The last file shows how text formatting can be combined (the modern term is “nested” for one text style that is inside another style of text) in a WordStar 4.0 file. This uses both underlined and bold text:
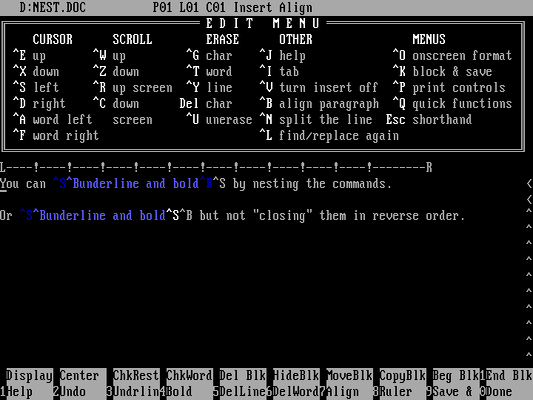
Using the program, we can examine the contents:
$ ./asciify NEST.DOC
Yo{u} ca{n} <19><2>underlin{e} an{d} bold<2>{} b{y} nestin{g} th{e} commands.<13><10>
<13><10>
O{r} <19><2>underlin{e} an{d} bold<19>{} bu{t} no{t} "closing{"} the{m} i{n} revers{e} order.<26><26><26>As in the first example, this WordStar file contains more than one line of text but the program displays output on a single line. I’ve added a line break after the carriage return and line feed pair so they are easier to read, although the output would actually appear on one line.
The output shows that nested formatting uses codes to turn on or off formatting when the formatting is “nested,” but WordStar 4.0 clears the formatting after the last “clear formatting” code. In this example, you can see that ASCII 19 starts and ends underlined text, and ASCII 2 starts and ends bold type.
A piece of history
It can be interesting to look “under the covers” to understand how a word processing file actually works. WordStar was an early desktop word processor that found great popularity with a variety of users, because it made writing documents easy. And with this sample program, we can see first-hand how WordStar stored its data. With a similar method, it becomes easy to write a program to convert WordStar files to plain text, or even convert them to other open formats such as HTML, Markdown, or LibreOffice.

Jim Hall is an open source software advocate and technical writer. At work, Jim is CEO of Hallmentum, an IT executive consulting company that provides hands-on IT Leadership training, workshops, and coaching.